Im Dezember 2019 war der Bundestagsabgeordnete Stephan Kühn (Bündnis 90/Grüne) zu einem Gespräch im Labor für Kfz-Mechatronik. Dabei ging es um den Beitrag der Fahrzeugautomatisierung zur Verkehrswende. Das vollständige Interview ist hier zu finden:
Mechlab-Neujahrsgruß
Das gesamte Mechlab-Team (siehe Bild, Dank an Hendrik für die Aufbereitung) wünscht allen Projektpartner ein gesundes neues Jahr und die erfolgreiche Fortsetzung der laufenden sowie tolle Ideen für neue Projekte.

Pointcloud Visualization at ZalaZONE

Introduction
We visited ZalaZONE late November this year. It is located in Zalaegerszeg, Hungary, one hour east of the Austrian-Hungarian border. With about 260 ha of space the ZalaZONE test ground provides test oppertunities and facilities for the testing of a wide range of future mobility concepts. Though a lot of the test ground is still „work-in-progess“, within our cooperation with ZalaZONE we were granted access to establish some test sequences on the completed testsections.
Following measurements were recorded on November 28th with mostly poor weather conditions (cloudy, occasional light to heavy rain). The measurements took place in different designated areas of the testground. The following interpretation discusses general effects, problems and characteristics of the lidar pointcloud(s) and partly introduces and discusses the testfield area in use.
The hardware being used consits mainly of some of the following parts:
- Cohda Mk5 (OBU – Onboard Unit & RSU – Roadside Unit)
- Ouster Lidar (64 layer laserscanner)
- Velodyne VLP-16 (16 layer laserscanner)
- ublox GPS
- Basler Cam (monochrome)
- processing hardware
In general both lidarscanners output a cloud of points, where each point is given not only with standard x,y,z position attributes, but also with such as intensity information for each point. This value is a very good possibility for filtering and interpretation as values of important street environment facilities are equipped with a retroreflective surface, thus reflecting a higher amount of light back to the laserscanner than nature would usually allow in a common diffuse reflection. A heatmap-like colored pointcloud is used to visualize the intensity of returned points. The colder the colour, the higher the value of given point.
A rudimentary map is imported into the visualizer. This is directly taken from a section defined and exported from OpenStreetMaps: see ZalaZONE at OpenStreetMaps here.
Dynamic Platform Measurement
The following test is recorded at the dynamic platform as part of ZalaZONEs testground. For more information about the different sections see here.
The measurement at this section was setup as follows: Half way up the access stretch there is a RSU set-up, supposed for communication with the vehicle’s OBU, as well as there is a retroreflective section (1m) of lanemarker (provided by 3M) put out on the right side of the road, overlaying the usual lanemarkings (see figure below). Only the Velodyne VLP-16 is running in this test, therefore there isn’t such a high resolution given between laserscan layers.
Some of the recorded data:
- gps positions of RSU and vehicle
- pointcloud data
- video data
- communication RSU <–> OBU
Measurement starts at the far end of the access stretch to the dynamic platform passing the RSU and M3’s lanemarker strip halfway down the stretch and continuing on to the free space of the dynamic platform. Returning to the starting spot afterwards (see video below).
Goals are the evaluation of communication aspects (such as signal strength) between RSU & OBU and the investigation of pointcloud behaviour.
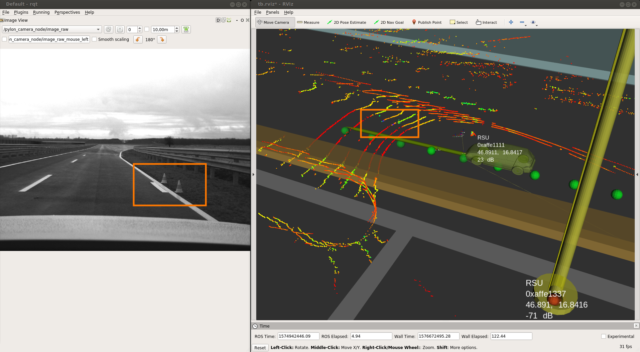
This snapshot shows the car at the moment of approach to the prepared lanemarker. The usual (standard) lanemarkings on the left and right of the lane are not retroreflective (colored red to orange, thus poor return value) in opposite to the prepared lanemarker: it’s value is very high and separates clearly from the ground around (indicated with green to blue color).
This video shows the vehicle moving along the straight, passing the RSU and lanemarker onto the platform section. Important to mention here is the absence of lidar information of the street ahead and furthermore as soon as we are level with the platform section, there is no information (no points) to the right of the vehicle retrieved from the laserscanner. This is to be explained with the bad weather conditions on site. The wet surface of the street causes a total reflection of the light beams sent out.
Smartcity Measurement
This test is recorded at the Smart City Zone as part of ZalaZONEs testground. For more information about the different sections see here.
The hardware in use corresponds with the former setup, additionally the Ouster Lidar is in use as well.
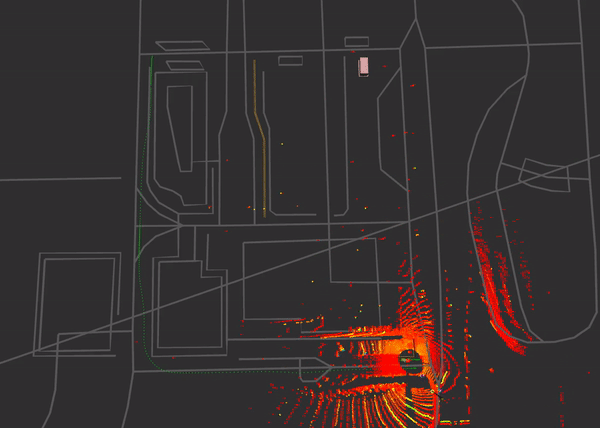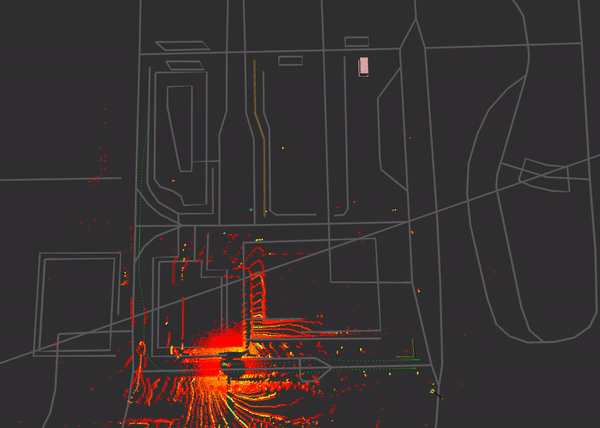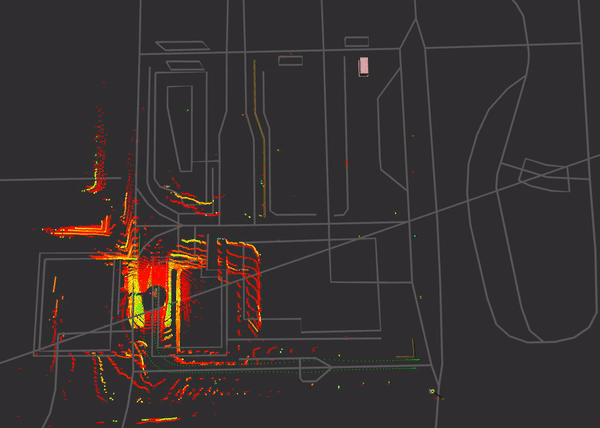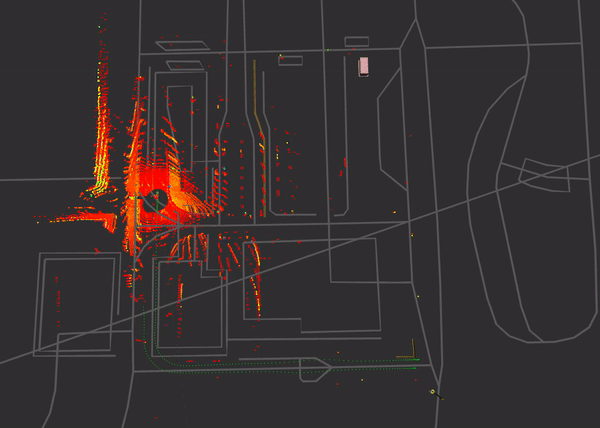
The RSU is set up on the bottom right, close to the starting point of the measurement, collected data corresponds to the data from the former measurement. Here again the pointcloud behaviour is targeted as well as the communication aspects.
The measurement procedure has the vehicle driving along the bottom of the map section, taking a right turn and doing a u-turn at the end of the street to take the way back. During this, a mixed driving profile with acceleration and deceleration at speeds ranging from 10-50 km/h is executed.
Street signs are well recognizable via intensity filtering (cold coloured points) of the pointcloud. The none-retroreflective (standard) lanemarkings are human-recognizable, but it’s hard to find a threshold as value differences compared to the street are not that significant. Still we retrieve more information from our surrounding environment as weather conditions are getting better and the street is not as wet as was with the former measurement.
An outgoing DENM is visualized as a pylon-texture during the ride around the section. In this case an aggressive deceleration leads to the output of this message. It is broadcasted to the surrounded vehicles.
Stay tuned for further information!
Neuer Artikel über das Mechlab-Team
In der aktuellen Ausgabe des HTW-Magazins „WissenD“ findet sich ein Artikel über das Mechlab-Team. Dabei geht es neben der Vorstellung der Forschungsaktivitäten auch um die neuen Anforderungen im Berufsbild des Fahrzeugtechnik-Ingenieurs. Bedingt durch die Digitalisierung liegen die neuen geforderten Kernkompetenzen im Bereich der Informatik und der Algorithmenentwicklung. Das Mechlab-Team hat bereits seit Jahren entsprechende Module und Praktikumsversuche im Angebot. Dabei steht immer die eigene Programmiererfahrung im Vordergrund, getestet werden die Programme dann am Prüfstand oder im Versuchsfahrzeug. Hier kann die HTW Dresden mit einem eigenen Prüffeld punkten, das komfortabel an das Fahrzeugtechnikum anschließt. Vergleichbare Studienbedingungen sind an keiner anderen Fachhochschule in Deutschland vorhanden.

ASAM International Conference 2019
Unter dem Motto Autonomous Driving – Standardized Virtual Development as a Key to Future Mobility tagte vom 10-11.12 die 4. ASAM International Conference 2019 im Dresdner Congress Center. Wesentliche Schwerpunkte waren insbesondere die Standardisierung der virtuellen Entwicklung, Verifizierung und Validierung sowie Künstliche Intelligenz / Machine Learning und Cyber Security.
Auch in diesem Jahr war das Team von mechlab mit einem eigenen Stand vertreten und demonstrierte u. a. die aktuellen Forschungsergebnisse aus dem Projekt GEwAF. Hervorgehoben wurde insbesondere die entwickelte Toolchain, welche sich aus der globalen Verkehrsflusssimulation SUMO sowie der lokalen Simulationsumgebung Unity3D und MATLAB bzw. ADTF als HAF-Funktionalität zusammensetzt.




VDI-Zertifikatskurs unter Mechlab-Leitung
Im kommenden Jahr startet das VDI-Wissensforum mit dem neuen Zertifikatslehrgang „Fachingenieur Fahrzeugautomatisierung VDI“ unter der Gesamtleitung von Prof. Toralf Trautmann. Zwei der 4 Pflichtmodule finden direkt an der HTW Dresden statt. Damit können die vorhandenen sehr guten technischen Möglichkeiten wie Prüffeld und Testfahrzeug intensiv zur praxisnahem Wissensvermittlung genutzt werden. Die Durchführung der Veranstaltungen in Dresden erfolgt durch das Zentrum für angewandte Forschung und Technologie e.V. (ZAFT e.V.). Unterstützt wird das Mechlab-Team durch Praxisbeiträge der Kooperationspartner FSD Fahrzeugsystemdaten GmbH (Zentrale Stelle nach StVG ) und TraceTronic GmbH. Der Kurs beginnt mit Modul 1 am 27/28.02 in Aachen. Alle Informationen finden sie hier:
https://www.vdi-wissensforum.de/lehrgaenge/fachingenieur-fahrzeugautomatisierung-vdi/

ROS-Simulink-Anbindung
Dank der systematischen Weiterentwicklung des Mechlab-Versuchsträgers durch das gesamte Mechlab-Team ist es nun möglich, das Fahrzeug auch aus Simulink heraus anzusteuern. Die Anbindung erfolgt durch den Betrieb des Steuerungsrechners als ROS-Knoten über die Ethernet-Schnittstelle. Zusätzlich sind die für eine Steuerung notwendigen ROS-Topics in Matlab zu implementieren. Das nachfolgende Video zeigt den Test eines PI-Reglers für die Längsführung (Tempomat). Die grundlegenden Zusammenhänge von Regler und Strecke sind damit für Studierende sehr gut nachvollziehbar. Künftig können nun die sehr umfangreichen Simulink-Regler zur Längs- und Querführung sehr einfach getestet und parametriert werden.
Automatisierte Fahrt verbessert
Durch die Einbeziehung eines Korrektursignals (Differential GPS) konnte die Ortung für die Fahrzeugführung des Mechlab-Versuchsträgers deutlich verbessert werden. Damit ist ab sofort eine stabile Fahrt mit Abweichungen im Bereich von nur noch 10 cm möglich. Das Video zeigt eine Testfahrt mit dem derzeitigen Entwicklungsstand, geregelt wurde auf die gestrichelte Mittellinie. In den kommenden Wochen erfolgt die weitere Paramteroptimierung zur Erhöhung der Fahrgeschwindigkeit. Sollte das System stabil nutzbar sein, ist als nächster Schritt die Fahrt im öffentlichen Verkehr vorgesehen. Das Versuchsfahrzeug verfügt über die entsprechende Ausnahmegenehmigung. Für die Freunde des Mechlab-Teams gibt es natürlich rechtzeitig eine persönliche Information.
Mechlab-Vortrag auf Automotive-Tagung
Prof. Toralf Trautmann stellte auf der Tagung „Innovative Transformation of the Automotive Industry“ auf Einladung des ungarischen Verkehrsministeriums den aktuellen Stand und die Herausforderungen im Bereich des automatisierten Fahrens vor. Neben verschiedenen Podiumsdiskussionen gab es eine große Industrieausstellung der in Ungarn vertretenen Hersteller und Zulieferer. Am nächsten Tag folgten weitere Gespräche an der Uni Budapest zu gemeinsamen Forschungsprojekten. Von besonderem Interesse ist dabei die Nutzung der gerade entstehenden Teststrecke „ZalaZone„. Für Ende November sind erste Testmessungen durch das Mechlab-Team vorgesehen.


Digitales Verkehrsschild im Testbetrieb
Auf dem Testfeld der HTW Dresden wurde für einen Zeitraum von einem Monat ein digitales Verkehrsschild durch die Firma Green Way Systems in Betrieb genommen. Für den Zeitraum von ca. einem Monat können darüber benutzerspezifische und standardisierte Verkehrssymbole eingeblendet werden.

