
The Point Cloud Library (PCL) offers great possibilities for processing large point clouds. In the following article the principle of different filters and its application on pointclouds from Velodyne Puck and Ouster OS1 LiDARs using ROS shall be described.
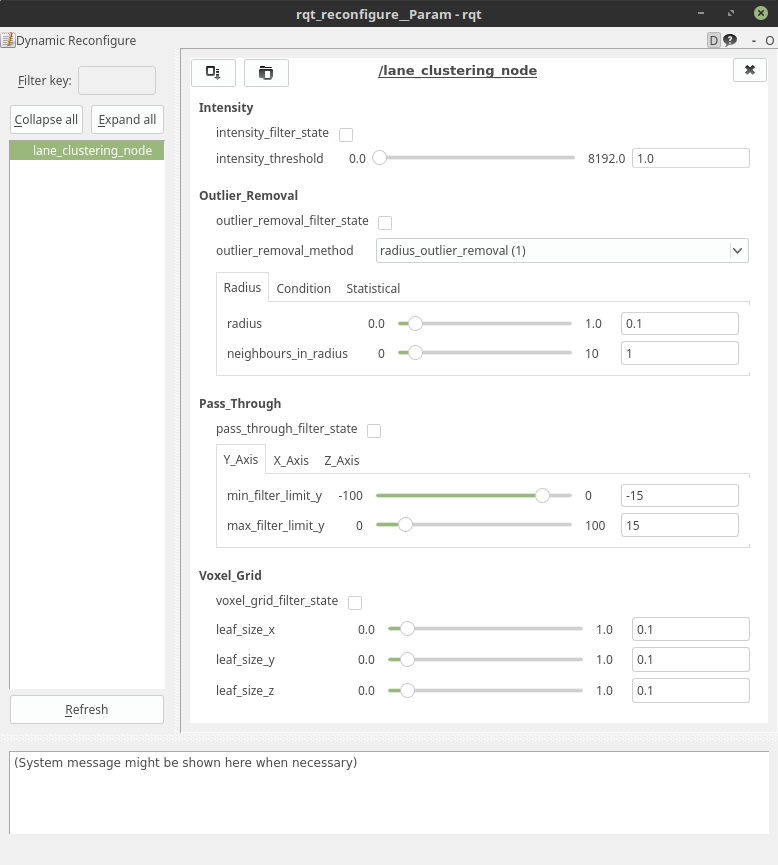
For quick configuration changes, all filter parameters can be changed via rqt dynamic reconfigure. So far 4 different types of filtration have been implemented:
Voxel Grid
This type of filter allows downsampling of large point clouds (PCL Voxel Grid Filter). The parameter leaf_size describes the length of a box in 3 dimensions, in which all points are reduced to one point.

Pass Through
A pass through filter allows to restrict point clouds in their dimensions (PCL Pass Through Filter). The parameters are the min and max value of the points in meters, which should (not) be filtered.

Outlier Removal
The library offers different types of filters to remove noise and outliers.
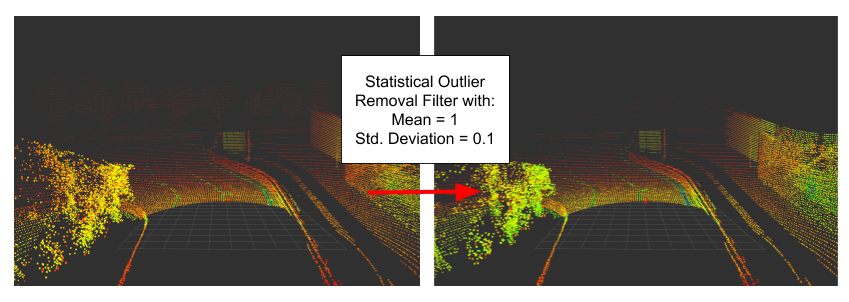
- Statistical Outlier Removal: The average distance from each point to its neighbours is calculated. Under the assumption that it is a gaussian distribution, a filtering can take place by using the parameters mean and standard deviation (PCL Statistical Outlier Removal Filter).
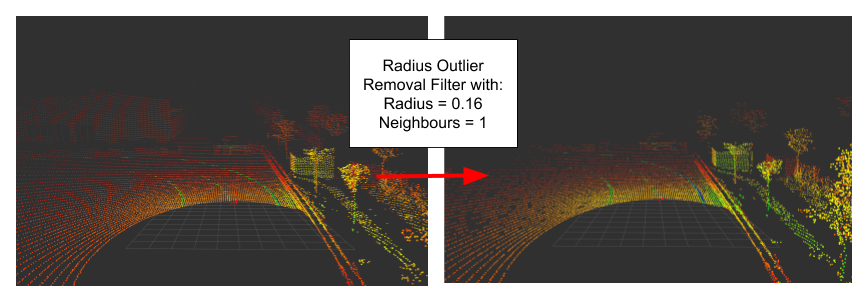
- Radius Outlier Removal: We define a certain number of points, which must be present within a radius (PCL Radius Outlier Removal Filter).
- Conditional Removal: The filtering object depends on the defined conditon. A condition could be described as a comparison between 2 thresholds. For example a point musst be musst be greater than and less than a given size (PCL Conditonal Outlier Removal Filter). It’s functionality can be compared to the Pass Through Filter.
Intensity Filter
The intensity filter is not part of PCL but the library in addition with Boost can be used to implement such a filter. A point in a cloud needs at least 3 informations (x, y, z) and optionally additonal an intensity or color informations. In our case we will define the PCL point type pcl::PointXYZI. Now a PCL point cloud pointer with the specified point type can be created as a typedef:
typedef typename pcl::PointCloud::Ptr PointCloudPtr
With Boost it’s easy to iterate through a sequence. Each point is assigned an intensity, which is compared afterwards:
BOOST_FOREACH (const pcl::PointXYZI &pt, input_cloud->points) {
if (pt.intensity > intensity_threshold)) {
output_cloud->points.push_back(PointXYZI_(pt.x,pt.y,pt.z,pt.intensity));
}
}
PointXYZI_ is a inline helper function because the PCL library does not provide a PointXYZI constructor for all needed fields (x, y, z, intensity). Now the whole filter can be implemented as a class method:
PointCloudPtr
LaneClustering::intensityFilter (PointCloudPtr input_cloud, double& intensity_threshold)
{
PointCloudPtr output_cloud (new pcl::PointCloud());
BOOST_FOREACH (const pcl::PointXYZI& pt, input_cloud->points) {
if (pt.intensity > intensity_threshold) {
output_cloud->points.push_back(PointXYZI_(pt.x,pt.y,pt.z,pt.intensity));
}
}
return (output_cloud);
}
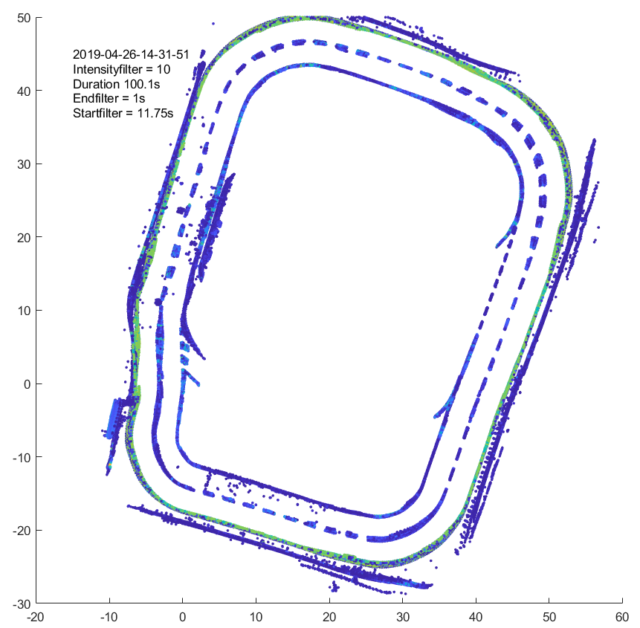
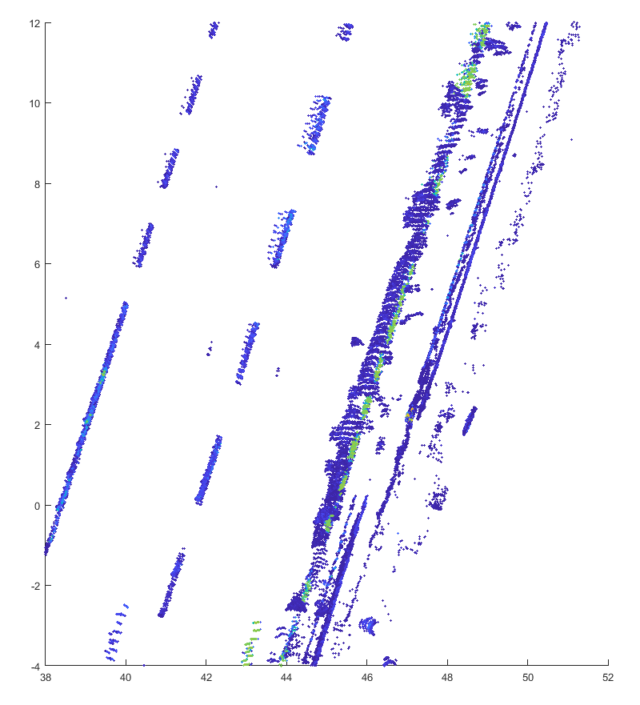
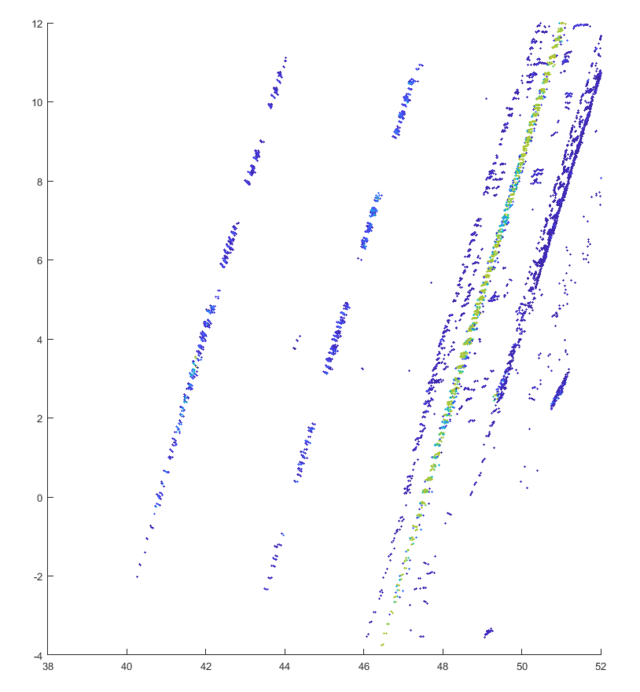
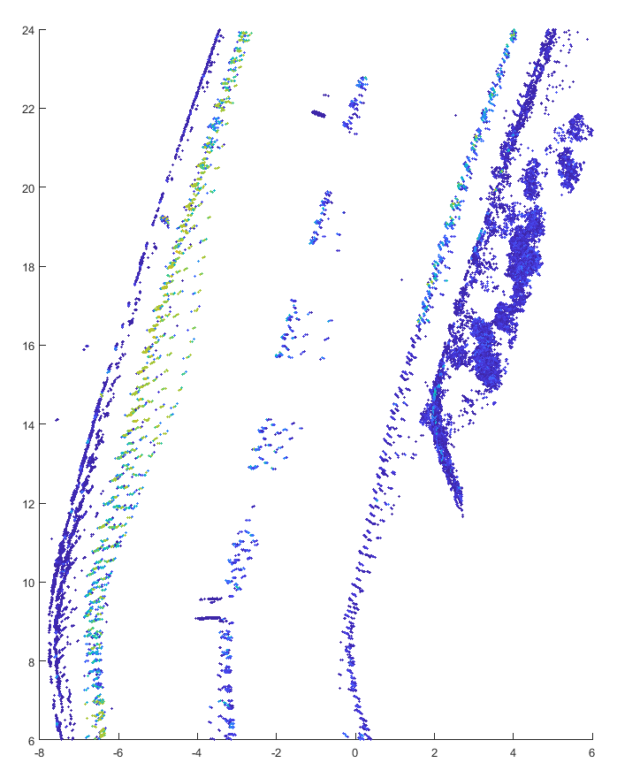
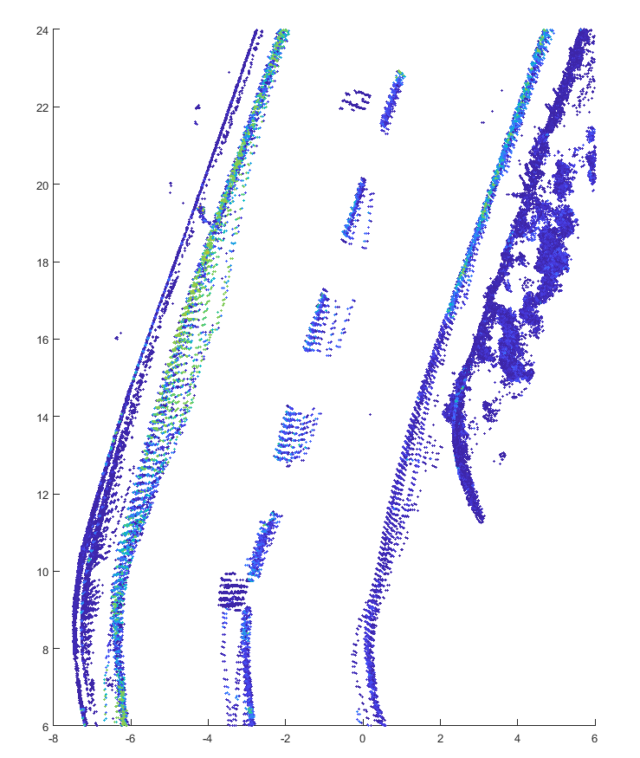
The following image shows the application of the filter with different intensity thresholds to a point cloud of an Ouster OS1 lidar with 64 layers:
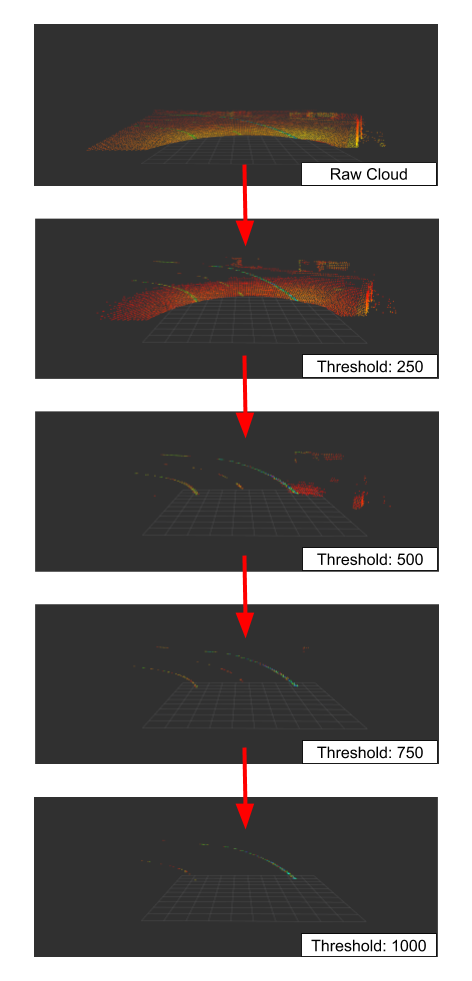
It is easy to see that many parts of the point cloud are filtered even at a very low limit value. From a value above 750 almost all points except the road markings are removed. If the limit value is further increased, parts of the track marking are also omitted and only the part with a retro-reflective marking remains.
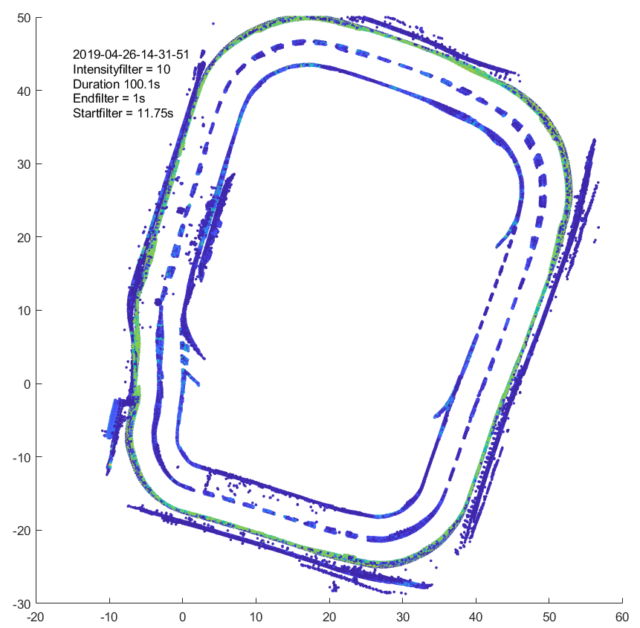
The following videos show the application of all filters on point clouds from a Velodyne Puck and an Ouster OS1 lidar.




































{kind=link}